In October 1967, the first IBM System/360 Model 91 was crated up in Poughkeepsie New York and shipped two hundred miles south to the Goddard Space Flight Center in Greenbelt Maryland, where it was installed as the centrepiece of the Tracking and Data Systems Directorate’s mission and data operations facility. It had been announced almost three years earlier as IBM’s answer to the CDC 6600 and as the most powerful general-purpose computer that the International Business Machines Corporation knew how to build. It would handle the orbit determination workload for almost every American Earth-orbiting science satellite of the late 1960s and early 1970s, the network data reduction for the Manned Space Flight Network and the Spacecraft Tracking and Data Acquisition Network, and a large fraction of the trajectory analysis support for missions running in parallel with the Apollo Real-Time Computer Complex at Houston.1 After acceptance testing, production operations began in January 1968.
Only fourteen Model 91 systems would ever be built.2 Four were retained inside IBM for development and field-engineering training. The remaining ten went to a small set of research customers: NASA Goddard, Columbia University in February 1969, UCLA by 1971 (where it was eventually plugged into the early ARPANET as one of the first nodes offering production computing services), the Stanford Linear Accelerator Center for high-energy particle physics analysis, and a handful of other sites that the open published record does not fully enumerate. The 91 was three years late to first ship, sold in tiny volume against the hundred-odd CDC 6600s that Seymour Cray’s team in Wisconsin would deliver between 1964 and 1972 (a story already covered in our previous post on the 6600 and the thirty-four people, including the janitor), and would be discontinued from the IBM catalogue by 1969.
Inside the floating-point unit of every one of those fourteen machines, however, was an algorithm. It had been worked out across 1965 and 1966 inside the IBM laboratory at Poughkeepsie by an engineer named Robert Tomasulo, written up by him in a nine-page paper that the IBM Journal of Research and Development received on 16 September 1965 and published in its January 1967 issue.3 The paper was titled, with characteristic IBM understatement, “An Efficient Algorithm for Exploiting Multiple Arithmetic Units.” It described a way of executing a stream of instructions in parallel by issuing them to several functional units, broadcasting their results on a shared communication bus, and using a small set of identifying tags to keep the dataflow straight. The algorithm was novel. It would also, after the 91 line was discontinued, drop almost completely out of commercial use for twenty-eight years, before being revived in November 1995 by a small Intel team in Hillsboro Oregon as the heart of the Pentium Pro microprocessor.

Today, in the spring of 2026, every high-performance central processing unit in the world is, in microarchitectural lineage, a descendant of Tomasulo’s 1967 algorithm. Apple Silicon. Intel Core. AMD Zen. IBM POWER. ARM big-cores. The high-performance RISC-V designs now in development. The reservation-station-and-broadcast scheme that Tomasulo wrote down at IBM Poughkeepsie in the autumn of 1965 is the universal organising principle of modern computer architecture.
This is the story of the machine that ran the algorithm; of the people who designed it and the person whose extension of it was lost for fifty-two years; of the antitrust drama that the machine triggered, the litigation database that vanished over a single weekend in January 1973, and the eventual revival in a converted storage room at Intel; and, since this is also a series about numerical weather prediction, of the connection back to operational forecasting – the three IBM System/360 Model 195 machines that the National Meteorological Center at Suitland Maryland would run as the operational backbone of United States weather forecasting from 1974 to 1981.
The Watson memo and the Jenny Lake retreat
Late August 1963 found IBM in something like a corporate panic. A small Minnesota company called Control Data Corporation, working out of a remote engineering laboratory on the bank of the Chippewa River in Wisconsin, had just announced a digital computer called the 6600 – and the 6600 was, by a factor of three, faster than anything IBM made. The 6600’s design team, the design team that had beaten IBM to the world’s most powerful computer, contained thirty-four people in total, including (the count was drawn from CDC’s own public employment numbers) a janitor. Thomas J. Watson Jr., IBM’s chairman and chief executive, dictated a one-page memo on 28 August 1963 asking his most senior engineers why the company with several thousand engineers had been beaten to the punch by a competitor whose entire engineering laboratory was, in his approximate count, smaller than the company’s average mid-level project team. The full story of the 6600, of Cray’s Wisconsin laboratory, and of Watson’s memo is told in the previous post in this series.4
The memo travelled inside IBM through early September 1963 and reached the company’s annual senior-management retreat at Jenny Lake Wyoming during the second week of that month. The Jenny Lake meeting that year was unusually consequential. By the time the senior IBM executives flew home it had committed the corporation to two large architectural projects.
The first was the System/360 family of mainframe computers, formally announced on 7 April 1964 – a single instruction-set architecture spanning a wide range of price and performance points, designed to unify what had been a fragmented IBM mainframe catalogue and to last (as it would) for fifty years and counting. The 360 was conservative in its individual implementations. Its scientific-computing crown was deliberately left unfilled.
The second project, intended to fill the scientific-computing crown, was the special-purpose machine that would become the System/360 Model 91. Announced in November 1964 – three months after the 6600’s first prototype was running in Chippewa Falls – the 91 was IBM’s deliberate competitive answer to Cray’s machine, designed for a mythical performance target of “more powerful than the 6600” and engineered around the philosophy that floating-point throughput should be maximised at any cost in hardware complexity.
A third project, more aggressive and largely secret, was authorised at the same retreat. It was internally designated Project Y, was reorganised at IBM Yorktown Heights as Advanced Computing Systems (ACS) in 1964, and would attempt to design a machine intended to be ten times faster than anything the 360 line could achieve.5 The ACS effort would target seven instructions per cycle of out-of-order execution – a level of architectural ambition that no commercial computer would actually reach until the mid-2000s. Its principal architect was John Cocke, a Charlotte-North-Carolina-born polymath who had earned a Bachelor of Science in Mechanical Engineering from Duke in 1946 and a Doctor of Philosophy in Mathematics from Duke in 1956 (his dissertation was titled The Regular Point) and had joined IBM in 1956 to work on the IBM 7030 Stretch.6 The ACS team also included a young engineer named Lynn Conway, who had been recruited from Columbia in 1964.7
Robert Tomasulo and the floating-point problem
While ACS was being staffed at Yorktown, the 360/91 was being engineered at IBM’s Poughkeepsie laboratory about thirty miles to the north. The 91 was to be a 360-architecture machine – it would run the same instruction set as the rest of the family, ensuring binary compatibility – but its central processing unit would be designed for raw scientific-computing throughput. Its target clock cycle was sixty nanoseconds. Its main memory cycle, on a sixteen-way-interleaved core array of two megabytes, would be 780 nanoseconds. Its instruction set would include both fixed-point and floating-point operations on 32-bit and 64-bit words.
The architectural challenge was that the floating-point arithmetic the 91 was being built to do quickly – multiplication, division, addition, subtraction, with full 64-bit precision – could not be done in a single sixty-nanosecond cycle. A floating-point multiplication on the 91’s hardware took six cycles. A division took eighteen. Even an addition took two. If the central processor issued instructions one at a time and waited for each to finish before the next began, the floating-point unit would spend most of its time idle while the rest of the machine waited.
The obvious solution was to design the floating-point unit as a small set of independent execution units running in parallel. A multiplier-divider could work on one operation while an adder worked on another; loads from memory could fetch new operands while previously-loaded operands were being arithmetic-ed. The problem was how to do this without breaking the program’s logical correctness – without having a later instruction’s results overwrite an earlier instruction’s input before that input had been used; without having a later instruction read a value before the earlier instruction that was supposed to produce it had finished.
This was the problem that Robert Marco Tomasulo was assigned to solve. Tomasulo had earned a Bachelor of Science in Electrical Engineering from Manhattan College in the Bronx and a Master of Science from Syracuse, and had joined IBM in 1956. By 1965 he had been at the company for nine years, working on Stretch and on its successor projects, and was the senior engineer responsible for the central control logic of the 360/91’s floating-point unit. His paper of January 1967 acknowledges three colleagues by name: Donald W. Anderson, who was the lead author of the companion paper on the 91’s machine philosophy and instruction handling, and Donald M. Powers, who co-authored the companion paper on the floating-point execution unit hardware itself; and W. D. Silkman, who – in Tomasulo’s exact words – “implemented all of the central control logic discussed in the paper.”8 Silkman is the unsung implementer of what is now universally known as Tomasulo’s algorithm. Few subsequent textbooks mention him.
The Common Data Bus
Tomasulo’s paper opens with an abstract that, in its first three sentences, gives the entire scheme away:
“This paper describes the methods employed in the floating-point area of the System/360 Model 91 to exploit the existence of multiple execution units. Basic to these techniques is a simple common data busing and register tagging scheme which permits simultaneous execution of independent instructions while preserving the essential precedences inherent in the instruction stream. The common data bus improves performance by efficiently utilizing the execution units without requiring specially optimized code. Instead, the hardware, by ‘looking ahead’ about eight instructions, automatically optimizes the program execution on a local basis.”9
Three things in that abstract are worth pulling out. First, the algorithm is described as a bus – a single, shared, broadcast communication channel that connects the producers of intermediate results to their consumers. Second, the algorithm is described as a tag scheme – each value in flight carries an identifying number that says where it came from and which subsequent instructions are waiting for it. Third, the optimisation is described as local and automatic – the programmer (or the compiler) writes ordinary sequential code, and the hardware extracts whatever parallelism it can find.
The paper then states, on page 27, what Tomasulo called the cardinal precedence principle, which we now teach undergraduates as the read-after-write hazard:
“No floating-point register may participate in an operation if it is the sink of another, incompleted instruction. That is, a register cannot be used until its contents reflect the result of the most recent operation to use that register as its sink.”10
The italics are in the original. This is the only architecturally-load-bearing constraint on the order in which instructions can actually execute. As long as the cardinal principle is preserved – a value is read by its consumers only after its producer has actually computed it – everything else can be reordered.
The mechanism Tomasulo proposed for preserving the cardinal principle, while extracting maximum parallelism, has two parts.
The first part is the reservation station. Each functional unit – the adder, the multiplier-divider – is fronted not by a single set of input registers but by a small set of input register slots, each one of which can hold the operands and the control information for a single in-flight instruction. The adder is given three reservation stations; the multiplier-divider is given two.11 An instruction that has been decoded but cannot yet execute (because one of its operands has not yet been computed by an earlier instruction) sits in a reservation station and waits for its operands to arrive. As soon as both operands are present, the reservation station’s instruction is dispatched to its functional unit. Multiple reservation stations on the same functional unit allow multiple in-flight instructions to be queued, ready to execute as soon as their data dependencies clear.
The second part is the Common Data Bus. The CDB is a single shared wire onto which any of the functional units, or any of the floating-point load buffers fetching values from memory, can broadcast a result. Every consumer in the machine – every operand slot in every reservation station, every busy floating-point register, every store buffer waiting to write to memory – carries a small number identifying the producer it is waiting for. Tomasulo called this number the tag. With six floating-point load buffers (tagged 1 through 6), three adder reservation stations (tagged 10, 11, 12), and two multiplier-divider stations (tagged 8 and 9), eleven possible producers can broadcast on the CDB; a four-bit tag suffices to name them. With three store-data buffers carrying their own tags, the total tag-storage cost was, in Tomasulo’s accounting, “17 four-bit tag registers” added to the floating-point unit.12
When a consumer’s tag matches the tag of the producer broadcasting on the CDB, the consumer captures the data. When all of a reservation station’s source slots have been filled in this way, the instruction in that station can execute. When an instruction executes, the result is broadcast on the CDB, and the consumers waiting for it – which may include both another reservation station for a downstream arithmetic operation and the architectural floating-point register that the program logically expects to hold the result – ingest the value in the same cycle.
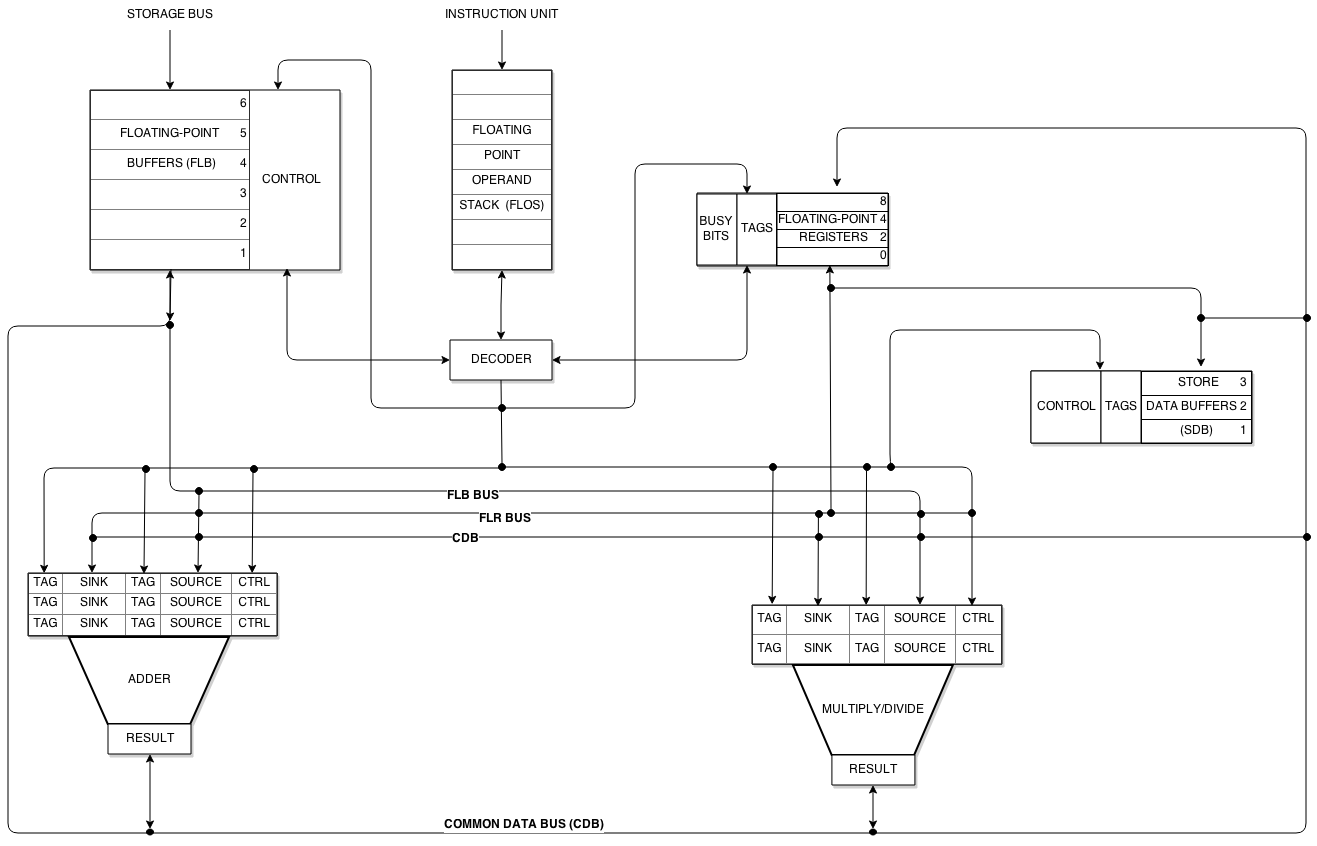
The mathematical effect of the tag scheme is something that the textbook tradition would later call register renaming, although Tomasulo himself never used that phrase: he wrote only of tags. The eleven possible producers in the 91’s floating-point unit are, effectively, eleven physical registers; the four architectural floating-point registers that the 360 instruction set exposes are not where intermediate values actually live during execution. They are pointers, identified by their current tag, into the larger physical pool. When two successive instructions both write the same architectural register – a pattern that would, in a simpler machine, force them to execute one at a time – they instead receive different reservation-station tags; their consumers wait for the appropriate tag; the architectural register’s tag is overwritten by whichever instruction finishes last; and the older value’s consumers have already captured what they needed via the CDB, regardless of whether the architectural register’s pointer has moved on.
The same mechanism dissolves the write-after-read hazard. An instruction that wants to write a register after a later instruction has already issued a read of it cannot conflict, because the reading instruction’s reservation station has already either captured the old value or recorded the old tag at issue time; the new writer is, from the reader’s perspective, irrelevant. Only the genuine read-after-write dependency survives. The reservation station holds the producer’s tag and physically waits for the producer’s CDB broadcast. The data flow itself is the constraint. Tomasulo’s algorithm runs at the speed of the longest read-after-write chain in the dataflow graph – which is, mathematically, the optimal schedule.
The closing example in the 1967 paper is, characteristically, drawn from the kind of code IBM’s customers actually ran. Tomasulo gives an eight-instruction inner loop – a multiply, an add, a load, a subtract, another multiply, another add, a store, and a branch – and notes that it is “a typical partial differential equation inner loop.” Without the Common Data Bus, one iteration of the loop runs in seventeen processor cycles. With the Common Data Bus, one iteration runs in eleven cycles. Tomasulo writes, on the last printed page of the paper:
“For this kind of code the CDB improves performance by about one-third.”13
That phrase – “this kind of code” – repays a closer look. In 1965, when Tomasulo wrote the paper, “a typical partial differential equation inner loop” meant numerical weather prediction, hydrodynamics, structural mechanics, or nuclear physics. Tomasulo’s own benchmark for the algorithm was the kind of computation that the first generation of general circulation models was about to consume in industrial quantities – although, as we will see, the actual operational weather forecasting that the 360 architecture would eventually do would happen on the slightly later 360/195, not on the 91.
The flaw
The 360/91 had one architectural flaw that would haunt it commercially and that, in the end, would keep Tomasulo’s algorithm out of the mainstream of microprocessor design for almost three decades. Floating-point exceptions on the 91 were imprecise.
When a floating-point operation underflowed or overflowed, the 91’s hardware did not, and could not, identify exactly which instruction had caused the exception. Instructions completed out of order. Multiple operations were in flight at once. By the time the exception was detected and the operating system was notified, the instruction stream had already moved on past the offending instruction. The OS could narrow the source of the exception to a small window of possibilities, but could not pin it precisely.
For a dedicated scientific batch machine running fixed numerical kernels, where the programmer expected to debug their own arithmetic and the operating system was a thin batch monitor, this was tolerable. For a general-purpose timesharing system running many programs simultaneously under virtual memory and demanding the ability to recover cleanly from a page fault or a divide-by-zero, it was not. Subsequent IBM 360 and 370 implementations specifically pulled back from the 91’s design philosophy, using less aggressive in-order pipelines that kept all interrupts precise. The 91’s combination of out-of-order execution and imprecise interrupts did not propagate inside IBM. It would, twenty years later, become the gating problem that the Pentium Pro architects would have to solve before Tomasulo’s algorithm could move into general-purpose computing.
Lynn Conway in San Jose, February 1966
Twenty miles south of where the 91 was being engineered, IBM’s Advanced Computing Systems group had relocated, in late 1965, from Yorktown Heights to a temporary facility on Sand Hill Road near Palo Alto – the future site of Stanford Industrial Park, then an emerging IBM West Coast research presence. The relocation was driven by the project’s leader, Herbert Schorr, who had moved his architecture team out from under the day-to-day administrative control of the Yorktown laboratory in order to design what Watson Jr. had told them in 1963 was a machine “to go for broke.”

Among the engineers Schorr had recruited was Lynn Conway, born 2 January 1938, who had taken her Bachelor of Science in Electrical Engineering from Columbia University in 1962 and her Master of Science the following year. As an undergraduate she had done an independent study with Schorr just before he left Columbia for IBM; she would later record in her memoir that “I must have made a good impression, for I was quickly recruited by IBM Research and in 1965 found myself at the T. J. Watson Research Center at Yorktown Heights, working on a highly proprietary and secretive supercomputer project, a project unknown even to many within the company.”14
By the autumn of 1965, on the West Coast, Conway was working on the most aggressive part of the ACS-1 design: how to schedule multiple instructions per cycle, dynamically, in hardware. The eventual ACS-1 design called for seven instructions to be initiated per cycle – one in the branch unit, three in the fixed-point unit, and three in the floating-point unit – a level of architectural width that would not appear in any shipped commercial computer until well into the 2000s.15 No technique then known could control such a width. Conway was assigned the problem of inventing one.
In her own account:
“Unaware that this was an open research question, I took it on as a design challenge and obsessed on it for over a month. I explored varying ways to represent and issue instructions, mentally juggling all aspects of the problem simultaneously – everything from mathematical abstractions, to architectural structures, to circuit-level implementations, but to no avail.”16
The breakthrough came in late 1965:
“In the fall of 1965, however, it suddenly beamed down to me. By holding pending instructions in a queue, and representing source and destination registers and functional units in unary positional form rather than in binary, I determined that it would be possible to scan the queue, resolve dependencies, and issue multiple instructions out-of-order, even when various entries were stalled.”17
The technique she invented was a generalisation of what Tomasulo was, around the same time and at the same company, working out for the floating-point unit of the 360/91. Conway’s scheme used a global pair of source and destination matrices over all registers, plus a busy vector over all functional units; it scanned the matrices each cycle for any row whose dependencies were met and whose target functional unit was free, and dispatched as many such instructions per cycle as the issue width allowed. Where Tomasulo’s algorithm was single-issue and confined to the floating-point unit, Conway’s was multi-issue and global.
She wrote it up in collaboration with Brian Randell (who had joined IBM Research in 1964 from English Electric and would in 1969 return to the United Kingdom to take the chair of computing science at Newcastle), Donald P. Rozenberg, and Donald N. Senzig. The four-author internal memorandum was completed at the Sand Jose facility on 23 February 1966. Its cover page, preserved in Conway’s archive at the University of Michigan, reads:
IBM CONFIDENTIAL MEMORANDUM TO: File SUBJECT: DYNAMIC INSTRUCTION SCHEDULING (DRAFT) ADVANCED COMPUTING SYSTEMS, SAN JOSE, February 23, 1966 L. Conway / B. Randell / D. P. Rozenberg / D. N. Senzig
Randell, Conway later wrote, was the one who coined the name. “An ACS colleague at the time, Brian Randell, coined a perfect name for the scheme, Dynamic Instruction Scheduling (DIS).”18
The DIS memorandum is twenty pages long. It describes a four-issue example on page four and a six-issue example on page eleven. Its conclusion summarises:
“In this paper we have described a dynamic scheduling mechanism for providing a look-ahead capability which enables the execution of instructions to be initiated out-of-sequence. In addition the mechanism is capable of controlling the simultaneous initiation of two or more instructions. The generality of register and functional unit interlocking provided by the mechanism may well be in excess of what is necessary for a given computer design.”19
The reference list of the DIS paper has only three entries. None of them is Tomasulo. Tomasulo’s IBM Journal paper would appear eleven months later, in January 1967. Conway and her three co-authors had no Tomasulo paper to cite. They had instead cited Gene Amdahl’s 1964 ONR symposium contribution on logical organisation of high-speed computers, the AFIPS 1964 paper by T. C. Chen describing the eventually-cancelled IBM System/360 Model 92 (the original phantom 6600-killer that the 91 was scaled back from), and James Thornton’s 1964 AFIPS paper “Parallel Operation in the Control Data 6600” – the canonical primary description of the 6600 Scoreboard mechanism.
The DIS paper of February 1966 thus stands as a generalisation of an idea that had been in the air at both IBM Poughkeepsie (Tomasulo, single-issue, floating-point only) and CDC Chippewa Falls (Thornton, scoreboard, single-issue, all execution units). Conway’s scheme extended the idea to multiple issue, made it global across all functional units, and packaged it for an architectural target – ACS-1 at seven issues – that no actual silicon could yet support. The memo was filed inside IBM. The ACS-1 hardware that DIS was meant to control was never built.
What happened to ACS
Project Y / ACS lasted at full strength from 1963 to 1968. By 1967 the ACS-1 design was mature enough that detailed simulation code, written largely by Conway, was producing performance estimates. By early 1968 the project was in trouble for reasons that had nothing to do with its technology. Gene Amdahl, by then one of IBM’s most senior architects, was arguing internally that the ACS team’s machine was incompatible with the System/360 architecture and would therefore fragment IBM’s software base; his proposed alternative was to redesign ACS for binary compatibility with the 360 instruction set. The political confrontation came to a head at a Saturday meeting in May 1968, at which Vincent Learson, then president of IBM, flew to California and committed the ACS team to System/360 compatibility. The original ACS-1 architecture was abandoned. The ACS team was restructured and most of its senior members eventually left the company. The lab was formally shut down in May 1969.
Conway, in her 2012 memoir, summarised the technical loss in two sentences:
“Apparently, neither Amdahl nor Evans nor other key IBM people had a clue about the novel DIS architectural innovations that had been made within the secretive project; the invention was shelved away and apparently lost in dusty technical reports.”20
She herself did not see the May 1969 closure. In 1968 she had separately become the subject of an IBM personnel decision. From her own account:
“At that same time in 1968, I was pioneering along another path, as well. I alerted HR at IBM that I was undertaking a gender transition to resolve a terrible existential situation I had faced since childhood. I was hoping to quietly maintain employment during that difficult period. However, the news escalated to IBM’s Corporate Executive Committee (including CEO T.J. Watson, Jr.), and I was summarily fired.”21
The firing was, Conway wrote elsewhere, “impulsively executed, as if in hot-anger.” It was ordered at the very top of the corporation, by the same chief executive who had personally launched ACS five years earlier. The summary dismissal severed Conway from her IBM identity, from her authorship of the DIS memorandum, and from any institutional access to her own work. She took a contract programming job at Computer Applications, Inc., in late 1968 and moved to Memorex Corporation as a digital systems designer in 1969. She did not, for the next thirty years, publicly disclose any of her IBM work.
In 1973 she joined Xerox PARC, where she was made head of the LSI Systems Area in 1976 and where, in collaboration with Carver Mead of Caltech, she co-authored the 1980 textbook Introduction to VLSI Systems and engineered the multi-project chip prototyping service that became MOSIS in 1981. The Mead-Conway methodology – scalable lambda-based design rules, the multi-project chip implementation service, the silicon-foundry-meets-fabless-customer separation that the modern semiconductor industry runs on – is what made it economically possible, by the early 1990s, for a fifty-million-transistor microprocessor to be designed by a single company and manufactured by another. Conway was the architect and principal author of the textbook, but, as she later wrote, “even though I was the architect and principal author of the book, we listed Mead as first author – to enhance the book’s credibility.”22
In late 1998 Conway entered the word “superscalar” into a search engine and discovered that Mark Smotherman, a professor of computing at Clemson University in South Carolina, had reconstructed the ACS history from internal IBM documents and was asking, in print, whether ACS-1 had been the first superscalar computer. Conway came out publicly as transgender in 1999 and began to recover the institutional record of her DIS work. In 2009 the IEEE Computer Society awarded her the Computer Pioneer Award with a citation reading:
“For contributions to superscalar architecture, including multiple-issue dynamic instruction scheduling, and for the innovation and widespread teaching of simplified VLSI design methods.”23
This citation is, as far as the public record is concerned, the single sentence that recognises both halves of her career: the suppressed 1966 DIS work and the 1980 VLSI revolution.
On 14 October 2020, fifty-two years after the firing, IBM held a virtual event for approximately twelve hundred of its employees titled Tech Trailblazer and Transgender Pioneer: Lynn Conway in conversation with Diane Gherson. Diane Gherson was IBM’s Senior Vice President for Human Resources. At the event, Gherson said, on the company’s behalf:
“I wanted to say to you here today, Lynn, for that experience in our company 52 years ago and all the hardships that followed, I am truly sorry.”24
The New York Times broke the story to the broader press on 21 November 2020 under the headline “52 Years Later, IBM Apologizes for Firing Transgender Woman.”
Lynn Conway died on 9 June 2024 at her home in Jackson Michigan, aged eighty-six. In the closing pages of her 2012 memoir she had written:
“I’ve also experienced a very special personal closure: The VLSI revolution enabled my DIS invention to finally come to life, to be implemented in silicon – and while I was still around to see it happen.”25
Where the fourteen machines went
While ACS was being dismantled, the 360/91 was being shipped, in a small trickle, to the customers IBM had announced it for. Pugh, Johnson and Palmer’s authoritative IBM’s 360 and Early 370 Systems gives the canonical figure of fourteen Model 91 systems built in total – four retained for IBM internal use, leaving ten outside customers.26 (Wikipedia gives the variant figure of fifteen built; the discrepancy is resolved if one counts the two specially-engineered 360/95 thin-film-memory variants alongside the standard Model 91 chassis. The defensible bracket is “fourteen to fifteen built, ten outside customers.”) The four sites firmly documented in the open record are:
NASA Goddard Space Flight Center, Greenbelt Maryland. Shipped October 1967, production operations from January 1968. Goddard’s centre director through this period was John F. Clark; the Tracking and Data Systems Directorate was led by Friedrich O. Vonbun. The 91 was the production engine for the Goddard Trajectory Determination System (GTDS), for orbit determination of the OAO, OGO, GEOS, ATS and Nimbus science satellites, and for tracking-network data reduction supporting the Manned Space Flight Network and the Spacecraft Tracking and Data Acquisition Network. Apollo trajectory work itself ran on five separate IBM 360/75 machines at the Real-Time Computer Complex in Houston, not on the Goddard 91.
Columbia University, New York City. Installed February-March 1969 in the Columbia Computer Center machine room, run by Director Kenneth M. King (who had been a Watson Fellow at Columbia’s earlier Watson Lab and had programmed demonstrations on the NORC). Columbia’s 91 was unusual among 91 installations for being a single-university procurement rather than a national lab or aerospace site. It was reportedly procured at a steep educational discount. It ran in production for over eleven years and was retired in November 1980; its console panel was relocated to the Computer History Museum at Mountain View California in June 2003, where it remains on public display.
UCLA, Los Angeles. Operating by 1971, run by the UCLA Campus Computing Network. UCLA’s 91 was, in the same year it became operational, plugged into the early ARPANET as one of the first nodes offering production computing services – “job submittal, a ‘mailbox’ system and FTP,” in Wikipedia’s summary. Reliability was poor; insider sources reported that the machine was frequently down because of water-cooling leaks. The pre-1969 UCLA general circulation model development under Yale Mintz and Akio Arakawa had been done on a separate IBM 7094 at the UCLA Medical School to which Mintz had weekend access; once the 91 was installed, UCLA GCM-derived codes were among the workloads it carried, although the canonical Mintz-Arakawa Mark I and Mark II runs of 1963-1969 had already taken place on the earlier machine.
Stanford Linear Accelerator Center, Stanford California. The accessioned 360/91 console at the Computer History Museum carries a placard reading literally “This machine was used at the Stanford Linear Accelerator Center.” SLAC was the rare instance of a major particle-physics laboratory taking an IBM rather than a CDC route at the high end. It ran high-energy event reconstruction and analysis from the SPEAR storage ring (commissioned 1972) and the earlier SLAC linac experiments.

The remaining five-or-so customer 91s are not enumerated in any single open primary source the present author has been able to locate. Pugh, Johnson and Palmer’s appendices on pages 380-409 of their book are the natural place to find the complete roster, but those pages were not fully accessible during this research.
The two System/360 Model 95 thin-film-memory variants were both sold to NASA, both formally accepted on 1 July 1968. One was installed at Goddard Space Flight Center in Greenbelt as the upgrade to the standard 91 in the Tracking and Data Systems Directorate; the other was installed at the Goddard Institute for Space Studies in Armstrong Hall at Broadway and 112th Street in Manhattan, on the Columbia University campus, where the institution’s founder Robert Jastrow was beginning to assemble what would, in the next decade, become James Hansen’s climate modelling group. The 95s used a one-megabyte thin-film memory, configured as sixteen units of sixty-four kilobytes each, with sixty-seven nanosecond access time – ten times faster than the 91’s standard core. Only two were ever built.
Where the operational forecasts ran
For a series about numerical weather prediction, the customer list above is striking for what it does not contain. The National Center for Atmospheric Research at Boulder, founded in 1960 by Walter Orr Roberts, was a CDC and Cray shop throughout the 1960s and 1970s. NCAR ran a CDC 3600 from 1963, a CDC 6600 (serial number seven, December 1965), and would replace it in 1971 with a CDC 7600. NCAR’s computing history archive records that in 1970 the lab benchmarked the IBM 360/195 against the CDC 7600 and chose the 7600. NCAR did not buy an IBM mainframe in this period.
The Geophysical Fluid Dynamics Laboratory, then on the Princeton campus at Forrestal Center, similarly avoided the IBM 360 line for its dedicated production machines. GFDL’s primary computational platforms across the 1960s and 1970s were, in sequence, the IBM 7030 Stretch (Suitland, then Princeton from 1968), a UNIVAC 1108 (1967-1973), and – most consequentially – the Texas Instruments Advanced Scientific Computer, serial number four, the only four-pipe ASC ever built, installed at Princeton in 1972 and serving as GFDL’s primary production engine until the late 1970s.27 The famous 1969 Manabe-Bryan paper that demonstrated the first coupled atmosphere-ocean general circulation model states explicitly, on page 787, that the calculation “required about 1200 hours of computing on a UNIVAC 1108.” Manabe’s even more famous 1975 paper with Wetherald, on the doubling-of-CO2 climate sensitivity, does not name a machine in its acknowledgements, but the timing aligns most cleanly with the TI ASC. GFDL did have limited shared access to a 360/91 and later a 360/195 at the Princeton University Computing Center between 1969 and 1975, but those machines were the university’s, not GFDL’s; they were not the platforms on which the foundational climate-modelling papers of those years were computed.
The 360 architecture’s clean operational-NWP heritage is elsewhere. Between 1974 and 1981, the National Meteorological Center at Suitland Maryland – the operational forecasting arm of the United States National Weather Service, the institutional ancestor of today’s NCEP – ran the IBM System/360 Model 195 as the production engine of United States operational weather forecasting. The 195 was the engineering successor to the 91, announced 20 August 1969, first delivered in 1971; about twenty were built. Its floating-point unit inherited the Tomasulo machinery of the 91 with cosmetic improvements and was paired with a more conventional cache memory hierarchy. The NMC procured three Model 195s, the first installed in March 1974 and the third in November 1975, under the directorship of Frederick G. Shuman, who had succeeded George Cressman as NMC director and would retire from the post in 1981. The NMC 195s ran the operational primitive-equation model that produced the United States’s daily six-day weather forecasts through the second half of the 1970s, including the 1978 transition to a higher-resolution model that exploited the 195’s increased throughput. The 360 architecture’s first customer for serious weather forecasting was, in other words, not GFDL or NCAR, but the operational shop at Suitland.
NMC’s 360/195s were eventually replaced in the mid-1980s by Cray Y-MP machines and, much later, by IBM RS/6000 SP systems. But the operational heritage of Tomasulo’s algorithm in United States numerical weather prediction is the seven-year run of the three Model 195s at Suitland, from 1974 to 1981 – the only window during which an IBM 360-architecture machine was the production engine of American operational forecasting.

Phantom machines and paper computers
While the 91 was being delivered, a separate, slower drama was unfolding around it. William C. Norris, founder and chief executive of Control Data Corporation, watched the 360/91’s announcement, the 360/92 announcement that preceded it (the 360/92 was the original IBM response to the 6600, announced briefly in 1964 and never built), and the 360/195 announcement that followed in August 1969, and concluded that IBM’s pattern of pre-announcing high-performance machines in tiny eventual production volumes was a deliberate market-foreclosure tactic against CDC. In December 1968, in the United States District Court for the District of Minnesota in Minneapolis, CDC filed Control Data Corp. v. International Business Machines Corp., docket number 3-68-312, before Judge Philip Neville.28 The complaint alleged monopolisation under section two of the Sherman Act and asked for treble damages.
A full page of the CDC complaint, the Reason magazine 1974 retrospective on the case records, was titled “Paper Machines and Phantom Computers.” It listed two distinct phantom-machine episodes. The first was the IBM 7030 Stretch of the early 1960s (announced 1956, originally promised at performance levels Stretch never delivered, ultimately shipped in only nine customer copies, with IBM publicly acknowledging the production version did not meet the design specification). The second was the System/360 Model 92 / Model 91 / Model 195 sequence: a series of IBM announcements of higher-performance systems, made when CDC was beginning to dominate the scientific computing market, that arrived years late, in tiny production volume, and only after CDC’s customer pipeline had been frozen by the announcements themselves.
One month after CDC filed, on 17 January 1969 – his last day in office before the inauguration of the Nixon administration on 20 January – Attorney General Ramsey Clark signed the United States Department of Justice’s own civil antitrust complaint against IBM under the same statute. United States v. International Business Machines Corp., docket number 69 Civ. 200, was filed in the Southern District of New York and assigned to Judge David N. Edelstein. The Nixon administration continued the case under Antitrust Division head Richard McLaren and Attorney General John Mitchell. Trial commenced 19 May 1975 and ran for almost six years. The transcript would eventually exceed 104 000 pages.29
Over the four years between the CDC filing and trial, CDC’s legal staff did something remarkable. They built a computerised guide to the IBM internal documents IBM had been ordered to produce in discovery. The IBM document base in the CDC case ran to approximately seventeen million pages. CDC’s legal staff produced about seventy-five thousand legal analyses of those documents, indexed and cross-referenced, kept on CDC’s own computer infrastructure – a database whose internal tooling ran on CDC machines, in an irony that was not lost on contemporary observers. The Department of Justice’s own antitrust lawyers, working on the parallel federal case, had been heavily dependent on the CDC database as the only available structured guide into the seventeen-million-page document mass.
Then, in January 1973, IBM and CDC settled.
The settlement was reached on Friday, 12 January 1973. The CDC database was not preserved. Per the contemporaneous record, “destruction of the computer base, on which the government relied in preparing for trial, would be a condition of settlement, with the destruction beginning at 3 p.m. on Jan. 12, the day agreement was reached, and ending the next day, a Saturday.” Magnetic tapes were erased; paper indexes were destroyed; the work-product analyses were removed from CDC’s possession. The destruction was completed over the weekend of 12-13 January 1973, before the public announcement of the settlement.
The terms of the settlement, as reported in the Wall Street Journal of 23 January 1973 and reconstructed across the secondary record by Reason 1974, by Pugh in Building IBM, and by the Cato Institute’s Levy and Welzer in their 1985 Regulation article “System Error: How the IBM Antitrust Suit Raised Computer Prices,” totalled approximately eighty million dollars in value to CDC:30
- IBM transferred its Service Bureau Corporation subsidiary to CDC for sixteen million dollars (Wall Street analysts at the time estimated SBC’s actual market value at sixty million);
- IBM agreed to purchase thirty million dollars of research and development services from CDC;
- IBM agreed to stay out of the data-processing services business in the United States for six years (1973-1979);
- IBM agreed to buy services from SBC for five years;
- IBM reimbursed CDC fifteen million dollars in legal fees.
The widely-circulated “six hundred million dollar” figure that has occasionally appeared in derivative summaries of the settlement is a misreading of CDC’s original-suit damages claim, not of the settlement value; the actual value to CDC, by every contemporary primary source, was approximately eighty million dollars.
The destruction of the CDC discovery database was the single most consequential element of the settlement. Three years after it, in 1976, Judge Edelstein in the parallel U.S. v. IBM case ruled that IBM had violated the spirit of his pretrial discovery order by allowing the destruction; the Justice Department had no remaining structured access to its own evidence. Edelstein wrote, on the disposition of the destruction:
“I don’t want a single document destroyed under any circumstances without the consent of this court.”
But his ruling came too late. The case continued for another six years after the destruction, but the Justice Department’s preparation never recovered the structured understanding the CDC database had given it. On 8 January 1982, Assistant Attorney General William F. Baxter of the Reagan administration filed a stipulation of dismissal stating that the United States had concluded that the case was “without merit.” Levy and Welzer would later argue, in the 1985 Cato Institute article, that the thirteen-year suit’s main empirical effect had been to keep IBM’s quality-adjusted prices high during the threat-of-breakup years 1969-1979 and to depress them only after the threat receded – the seminal “antitrust is counterproductive” critique of the IBM litigation.
By the time the case was dismissed, the 360/91 had been out of production for thirteen years. The 360/195 had been out of production for seven. The IBM mainframe business had moved on to the System/370 family. CDC had moved on to the STAR-100 (a flop in three units), the Cyber 200 series, and the failed CDC 8600 project that had driven Cray to leave the company in 1972 to found Cray Research, Inc. Tomasulo’s algorithm had not appeared in any new commercial computer in the meantime. The reservation stations and the Common Data Bus that IBM had built fourteen times into the 91 and twenty times into the 195 sat, between 1971 and 1995, almost entirely unused.
The 28-year quiet
There were four reasons the algorithm went quiet.
The first was the imprecise interrupt problem. Tomasulo’s algorithm in its 1967 form was incompatible with the kind of paged-virtual-memory operating systems that scientific timesharing and commercial general-purpose computing increasingly demanded. The fix was not published until June 1985, when James E. Smith and Andrew R. Pleszkun of the University of Wisconsin-Madison presented a paper at the 12th International Symposium on Computer Architecture in Boston titled “Implementation of Precise Interrupts in Pipelined Processors.” Smith and Pleszkun’s paper described five different mechanisms for combining out-of-order execution with precise interrupts; the fourth, the reorder buffer or ROB, was the one that became the textbook standard. The ROB is a circular FIFO queue of in-flight instructions, allocated in program order at issue, in which results live until the instruction reaches the head and retires, at which point the result is committed to architectural state.31 Smith and Pleszkun’s CRAY-1S simulations showed the ROB cost only about three percent in performance compared to in-order completion. The combination of Tomasulo’s reservation stations (for renaming) plus Smith-Pleszkun’s reorder buffer (for in-order retirement) is the design pattern that every modern out-of-order processor implements.
The second was transistor budget. The 91’s reservation-station-and-CDB hardware would, in modern accounting, be the equivalent of perhaps thirty thousand transistors – a small fraction of a 2026 microprocessor but more than the entire Intel 8086 of 1978 (which used twenty-nine thousand). Until the late 1980s no microprocessor had a transistor count that could comfortably accommodate a forty-entry reorder buffer and a twenty-entry reservation station. The microprocessor era’s first economically viable substrate for Tomasulo’s algorithm was the half-micron CMOS technology that became available in the early 1990s.
The third was that the 1980s were the decade of the Reduced Instruction Set Computer. David Patterson’s 1985 Communications of the ACM paper “Reduced Instruction Set Computers” – the canonical exposition of the RISC argument that simple instructions executed in tightly scheduled in-order pipelines beat complex instructions interpreted by microcode – treated both the CDC 6600 Scoreboard and the IBM 360/91 Tomasulo machinery as the classical examples of dynamic hardware scheduling, and offered the RISC philosophy explicitly as an alternative.32 The argument was that a compiler could schedule instructions statically against a simple instruction set, and that dedicating hardware to dynamic scheduling was wasted silicon. The argument was widely persuasive throughout the 1980s. The RISC chips that shipped before about 1995 – MIPS R2000 / R3000 / R4000, SPARC v7 / v8 / v9, ARMv1 through v4, PA-RISC 1.x, DEC Alpha 21064 and 21164 – were either fully in-order or used only minimal scoreboarding. Tomasulo’s algorithm sat outside the architectural fashion of an entire decade.
The fourth was that the Common Data Bus is, at high clock rates, a wire-routing problem. A single bus broadcasting to all reservation stations every cycle is tractable at one hundred megahertz on copper traces; at five gigahertz on aluminium-oxide-isolated CMOS interconnect it is a fundamental limit on reservation-station count. The architectural fix would turn out to be to break the CDB into per-functional-unit forwarding networks, and to keep the unified reservation-station array small (the Pentium Pro’s was twenty entries) and the reorder buffer larger. But this engineering required sub-micron CMOS to be cost-effective.
A converted storage room in Hillsboro, 1990
In June 1990, Robert Pickett “Bob” Colwell – born 28 December 1953, educated at the University of Pittsburgh and Carnegie Mellon (PhD 1985, on the iAPX 432 and the RISC versus CISC trade-off), trained at Multiflow Computer in Branford Connecticut where he had spent five years designing very-long-instruction-word minisupercomputers – joined Intel as a senior central-processing-unit architect at the company’s Hawthorn Farm campus in Hillsboro Oregon. He had been hired by Fred Pollack, who was running the team that would design Intel’s next-generation x86 chip after the Pentium. Within three months of arrival Colwell had been asked to write an annotated bibliography of architectural literature relevant to the next chip; in September 1990 the team committed to designing it as an out-of-order processor.
Colwell was joined on what became the P6 design team by four other principal architects. David Bruce Papworth, also from Multiflow, was the second senior chip architect. Glenn J. Hinton, a Brigham Young University graduate who had been on Intel’s i960 team in Oregon, brought in over ninety patents from eight previous Intel designs. Andrew F. “Andy” Glew, a McGill graduate (BSc) and University of Illinois at Urbana-Champaign master’s recipient (1991), invented what became the chip’s Register Alias Table – the renaming mechanism that mapped the eight x86 architectural registers onto a forty-entry physical pool. Michael Fetterman was the fifth member of the canonical patent-team.

The team initially had no permanent meeting space. Per Colwell’s 2009 oral history:
“We literally met in a storage room doing the early P6 architectural design, because we couldn’t find anywhere else that we could routinely meet. We only got into that storage room because Dave Papworth was so creative with jimmying the door lock with his employee ID.”33
The architectural plan, as it emerged across 1990 and 1991, was to build an x86-compatible processor whose front end decoded each x86 instruction into one or more micro-operations (the team called them “uops”), and whose back end ran those micro-operations through a Tomasulo-plus-reorder-buffer engine that would have been recognisable, in concept, to Robert Tomasulo himself. Three independent units would do the work: a fetch and decode unit feeding the rename and dispatch logic in program order; a dispatch and execute unit running the renamed micro-operations out of order through five execution ports against a unified twenty-entry reservation station; and a retire unit pulling completed micro-operations off the head of a forty-entry reorder buffer, in program order, and committing their results to the architectural register file.
The team’s choice of the name “reservation station” for the renamed-micro-op queue was deliberate. Asked about the academic and historical ancestors of the design, Colwell volunteers, in the same oral history:
“We should also say that the 360/91 from IBM in the 1960s was also out of order, it was the first one and it was not academic, that was a real machine. Incidentally that is one of the reasons that we picked certain terms that we used for the insides of the P6, like the reservation station that came straight out of the 360/91.
“At one point NCR was a little panicky about whether they should really commit to Intel because what this P6 chip might not work. They hired Mike Flynn from Stanford to come and spend a day with us. I was presenting to him and suddenly Mike Flynn got really agitated and he stopped and he said, I do not like the fact that you guys have started with terms, that you do not even mean the same thing by them. These people were here ahead of you and this isn’t fair, you are not showing respect for your ancestors. I said, well Mike, we named it specifically that to try to give honor where it’s due, we know we did not invent this topic, that is the first time I ever saw it was the 360/91, so I used its name even though I know it is not quite exactly the same.”34
Twenty-eight years after Tomasulo published the algorithm, the architects building the chip that would put it in every desktop computer in the world were arguing about whether they had the right to use the word he had coined. Michael J. Flynn, the Stanford professor whose 1972 paper had defined the standard taxonomy of parallel computer architectures, had himself been at IBM Poughkeepsie in 1962-1965 working on the same Project Y / SPREAD pipeline that became the 360/91. He knew what reservation stations originally were. The Intel team picked the word, Colwell said, “specifically to try to give honor where it’s due.”

The Pentium Pro shipped on 1 November 1995. The launch part ran at 150 megahertz on a 0.6 micron BiCMOS process and contained 5.5 million transistors. Its forty-entry reorder buffer and twenty-entry unified reservation station with five issue ports were the first commercial implementation of the Tomasulo-plus-Smith-Pleszkun design pattern that the Hennessy and Patterson textbook tradition had been canonising since the 1990 first edition of Computer Architecture: A Quantitative Approach. The 150 megahertz part with 256 kilobytes of integrated level-two cache launched at $974.35 Within five years, the Pentium Pro design pattern – often called the P6 microarchitecture internally at Intel – had been fielded by all of Intel’s major competitors: AMD’s K5 (March 1996), MIPS’s R10000 (January 1996), DEC’s Alpha 21264 (October 1998), AMD’s K7 / Athlon (June 1999). IBM’s POWER1 of January 1990 had been the earliest commercial out-of-order superscalar microprocessor, with limited register renaming on floating-point loads only; POWER3 in 1998 was IBM’s first full Tomasulo-plus-reorder-buffer implementation in the Power line.
By 2001 every high-performance microprocessor sold in the world was a Tomasulo descendant. The P6 itself remained the ancestral microarchitecture of Intel’s mainstream desktop chips through Pentium II (1997), Pentium III (1999), Pentium M (2003), Intel Core (2006), Core 2 (2006), Nehalem (2008), Sandy Bridge (2011), Haswell (2013), Skylake (2015), and the Sunny Cove and Golden Cove and Lion Cove cores of the 2020s. Apple’s Silicon M-series cores – Firestorm in the M1 of November 2020, with what reverse-engineering work suggests is approximately a six-hundred-and-thirty-entry register rename and an out-of-order window of more than a thousand in-flight instructions – run, in microarchitectural pedigree, the same algorithm.36 AMD’s Zen line, ARM’s Cortex-X cores, the high-performance RISC-V designs now in development: every one is a Tomasulo machine with a Smith-Pleszkun reorder buffer.
What Cocke did with the rest of his career
While Conway was rebuilding her professional life and Tomasulo’s algorithm was sitting on a shelf, John Cocke was doing something else inside IBM. He had survived the ACS dismantling of 1969 and had been moved to IBM’s Yorktown Research division. There, beginning around 1974, he led the development of a small experimental machine called the 801 – a one-megahertz minicomputer, built in a single rack at Yorktown, whose core architectural argument was the inversion of everything Cocke had spent the previous fifteen years building.
The 801’s argument was that the way to get high performance was not to put an aggressive out-of-order multiple-issue scheduler on top of a complex instruction set; it was to design a simple instruction set, a single-issue load-store architecture with thirty-two general-purpose registers and a few dozen instructions, against which a sufficiently good optimising compiler could extract high static performance from a simple in-order pipelined processor. This was the Reduced Instruction Set Computer philosophy. The 801 was the prototype for what would become IBM’s RT-PC of 1986 and IBM’s POWER1 of January 1990, by which time the Berkeley RISC and Stanford MIPS academic projects had independently arrived at the same conclusion.
The intellectual paradox of Cocke’s career is that the same architect spent thirty years arguing two opposite cases. The Stretch, ACS-1, and 360/91 line said: extract performance from sequential code by building elaborate hardware schedulers that look ahead through the instruction stream, dispatch out of order, and rename registers under the cover of tags. The 801 line said: extract performance from sequential code by building simple hardware that the compiler can schedule statically. Cocke – according to his various oral histories – never quite reconciled the two arguments in print. He simply moved from the first to the second around 1972, kept moving, and lived to see both arguments fused, in February 1990, when IBM shipped the POWER1 – a RISC instruction set, hardware register renaming on floating-point loads, multiple-issue execution, in-order completion – under his architectural sponsorship.
Cocke received the ACM Eckert-Mauchly Award in 1985, the Turing Award in 1987, the National Medal of Technology in 1991, the National Medal of Science in 1994, and the Seymour Cray Award in 1999 (the first recipient of that prize). He was made a Computer History Museum Fellow in 2002 and died on 16 July 2002 in Valhalla New York after a series of strokes, at the age of seventy-seven.37 Joel Birnbaum, his colleague at IBM Research and later at Hewlett-Packard, would describe Cocke as “the smartest man I ever met.” Lewis Branscomb, IBM’s chief scientist in the 1970s, was widely quoted as saying that Cocke had “an IQ higher than his blood cholesterol level.” He was a heavy smoker; Andrew Orlowski’s Register obituary remembered him for “a trail of cigarette butts (the fresher, the closer he was likely to be).” His PhD dissertation at Duke, completed in 1956, had been titled simply The Regular Point.
The intellectual arc that connects ACS-1 in 1965 to POWER1 in 1990 – and through POWER1 to the entire modern ecosystem of high-performance RISC-and-out-of-order processors – runs through Cocke. When the Pentium Pro shipped in 1995 it was decoding x86 instructions into RISC-like micro-operations in its front end and feeding them to a Tomasulo-style reservation-station array in its back end. That hybrid – a CISC-decoded RISC-internal Tomasulo machine with a Smith-Pleszkun reorder buffer – is also Cocke’s argument, applied at a level of integration that nothing in 1965 or 1972 could have built but that 1995 finally could.
Tomasulo himself
Robert Tomasulo worked at IBM until his retirement; he never published a major paper after 1967, although he is credited as a co-architect on several internal projects through the 1970s and 1980s. He gave the inaugural University of Michigan Computer Science and Engineering Distinguished Lecture on 30 January 2008, two months before he died, on the subject of the algorithm that bears his name. The video record of that lecture is preserved by Michigan but is access-controlled.
In 1997, the Association for Computing Machinery awarded him the Eckert-Mauchly Award – the discipline’s highest recognition for contributions to computer architecture and systems. The full citation, as recorded in the awards database, runs to a single phrase:
“For the ingenious Tomasulo’s algorithm, which enabled out-of-order execution processors to be implemented.”38
Three decades earlier, on the last printed page of the IBM Journal of Research and Development’s January 1967 issue, he had given his own one-sentence summary:
“Two concepts of some significance to the design of high-performance computers have been presented. The first, reservation stations, is simply an expeditious method of buffering, in an environment where the transmission time between units is of consequence. … The second, and more important, innovation, the CDB, utilizes the reservation stations and a simple tagging scheme to preserve precedence while encouraging concurrency.”39
In thirty years between the two sentences, the algorithm built into fourteen IBM 360/91s in 1967 had become the algorithm built into every microprocessor in the world. The fourteen machines themselves had been long since scrapped or museum-cased. The seventy-five thousand legal analyses CDC’s lawyers had compiled to prove that IBM had abused them as phantom announcements had been incinerated over a Friday afternoon and Saturday in January 1973. The aggressive seven-issue ACS-1 architecture that Lynn Conway, Brian Randell, Donald Rozenberg, and Donald Senzig had designed in San Jose in February 1966 had been generalised as Dynamic Instruction Scheduling – a scheme that would not be commercially implemented at full architectural width until decades later, when the silicon could finally support what the architecture had always been able to specify. Robert Tomasulo lived to see the algorithm become canonical in every undergraduate computer-architecture textbook. Lynn Conway lived to see the silicon implement the multi-issue extension she had invented. Robert Tomasulo died in March 2008. Lynn Conway died in June 2024.
The 360/91 itself, on permanent display, sits in the Computer History Museum in Mountain View California, its console panel open to visitors – the same Columbia University machine that ran in production for over eleven years and was retired in November 1980. It is one of perhaps three surviving 360/91 chassis or significant component sets in the world. There are no surviving 360/95 thin-film machines. The three NMC 360/195s are scrapped. The Goddard 360/91 and the SLAC 360/91 chassis are no longer extant.
The fourteen machines did not last. The algorithm did.
Footnotes
References
- Anderson, D. W., Sparacio, F. J., and Tomasulo, R. M., “The IBM System/360 Model 91: Machine Philosophy and Instruction-Handling,” IBM Journal of Research and Development 11(1):8-24, January 1967.
- Anderson, S. F., Earle, J. G., Goldschmidt, R. E., and Powers, D. M., “The IBM System/360 Model 91: Floating-Point Execution Unit,” IBM Journal of Research and Development 11(1):34-53, January 1967.
- Boland, L. J., Granito, G. D., Marcotte, A. U., Messina, B. U., and Smith, J. W., “The IBM System/360 Model 91: Storage System,” IBM Journal of Research and Development 11(1):54-68, January 1967.
- Colwell, R. P., The Pentium Chronicles: The People, Passion, and Politics Behind Intel’s Landmark Chips, IEEE Computer Society / Wiley, 2006.
- Colwell, R. P., oral history interviewed by Paul N. Edwards, 24-25 August 2009, SIGMICRO Oral Histories.
- Colwell, R. P., and Steck, R. L., “A 0.6 micron BiCMOS Processor with Dynamic Execution,” Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, February 1995.
- Conway, L., Randell, B., Rozenberg, D. P., and Senzig, D. N., “Dynamic Instruction Scheduling (DRAFT),” ACS Memorandum, IBM Advanced Computing Systems, San Jose, 23 February 1966.
- Conway, L., “Reminiscences of the VLSI Revolution: How a series of failures triggered a paradigm shift in digital design,” IEEE Solid-State Circuits Magazine 4(4):8-31, Fall 2012.
- Conway, L., “IBM-ACS: Reminiscences and Lessons Learned from a 1960’s Supercomputer Project,” in Jones, C. B., and Lloyd, J. L., eds., Dependable and Historic Computing, Springer, Berlin, 2011, pp. 185-224.
- Edwards, P. N., A Vast Machine: Computer Models, Climate Data, and the Politics of Global Warming, MIT Press, Cambridge MA, 2010.
- Hennessy, J. L., and Patterson, D. A., Computer Architecture: A Quantitative Approach, Morgan Kaufmann, six editions 1990-2017.
- Levy, D., and Welzer, S., “System Error: How the IBM Antitrust Suit Raised Computer Prices,” Regulation 9(5/6):27-33, September-October 1985.
- Manabe, S., and Bryan, K., “Climate Calculations with a Combined Ocean-Atmosphere Model,” Journal of the Atmospheric Sciences 26(4):786-789, July 1969.
- Manabe, S., and Wetherald, R. T., “The Effects of Doubling the CO2 Concentration on the Climate of a General Circulation Model,” Journal of the Atmospheric Sciences 32(1):3-15, January 1975.
- Mead, C., and Conway, L., Introduction to VLSI Systems, Addison-Wesley, Reading MA, 1980.
- Murray, C. J., The Supermen: The Story of Seymour Cray and the Technical Wizards Behind the Supercomputer, Wiley, 1997.
- NOAA, Activities FY 80, Plans FY 81: With a Review of Twenty-Five Years of Research 1955-1980, Geophysical Fluid Dynamics Laboratory, September 1980.
- Patterson, D. A., “Reduced Instruction Set Computers,” Communications of the ACM 28(1):8-21, January 1985.
- Pugh, E. W., Building IBM: Shaping an Industry and Its Technology, MIT Press, Cambridge MA, 1995.
- Pugh, E. W., Johnson, L. R., and Palmer, J. H., IBM’s 360 and Early 370 Systems, MIT Press, Cambridge MA, 1991.
- Smith, J. E., and Pleszkun, A. R., “Implementation of Precise Interrupts in Pipelined Processors,” Proceedings of the 12th Annual International Symposium on Computer Architecture, Boston MA, June 1985, pp. 36-44.
- Smotherman, M., and Spicer, D., “Historical Reflections: IBM’s Single-Processor Supercomputer Efforts,” Communications of the ACM 53(12):28-30, December 2010.
- Smotherman, M., “IBM Advanced Computing Systems (ACS) – 1961-1969,” historical reconstruction website, Clemson University.
- Tomasulo, R. M., “An Efficient Algorithm for Exploiting Multiple Arithmetic Units,” IBM Journal of Research and Development 11(1):25-33, January 1967.
- Wall Street Journal, “Litigation, CDC Settlement Seen As Set Back by Others Suing IBM,” 23 January 1973, Computer and Communications Industry Association collection, Charles Babbage Institute, University of Minnesota.
-
NASA Goddard Mission and Data Operations IBM 360 User’s Guide, NASA-TM-X-69900 (Balakirsky, July 1973), document the 91’s role in the Tracking and Data Systems Directorate. The Goddard 91 is also referenced in NTRS technical reports 19690008667 and 19760017203. Apollo Real-Time Computer Complex used five separate IBM 360/75 machines at the Manned Spacecraft Center in Houston, not the 91. See also F. O. Vonbun’s archive at MIT Digital Apollo for the Tracking and Data Systems context. ↩
-
Pugh, E. W., Johnson, L. R., and Palmer, J. H., IBM’s 360 and Early 370 Systems, MIT Press, Cambridge MA, 1991, pp. 380-409, give the canonical figure of fourteen Model 91s built. Wikipedia gives the variant figure of fifteen including the two Model 95 thin-film variants. The number of “outside customer” installations is consistently cited as ten. See https://en.wikipedia.org/wiki/IBM_System/360_Model_91 for the production-count discussion. ↩
-
Tomasulo, R. M., “An Efficient Algorithm for Exploiting Multiple Arithmetic Units,” IBM Journal of Research and Development 11(1):25-33, January 1967, DOI 10.1147/rd.111.0025. Received by the journal 16 September 1965. The companion papers in the same issue are Anderson, D. W., Sparacio, F. J., and Tomasulo, R. M., “The IBM System/360 Model 91: Machine Philosophy and Instruction-Handling,” pp. 8-24; Anderson, S. F., Earle, J. G., Goldschmidt, R. E., and Powers, D. M., “The IBM System/360 Model 91: Floating-Point Execution Unit,” pp. 34-53; and Boland, L. J., et al, “The IBM System/360 Model 91: Storage System,” pp. 54-68. PDF of Tomasulo’s paper mirrored at https://www.cs.virginia.edu/~evans/greatworks/tomasulo.pdf. ↩
-
The Watson “thirty-four people including the janitor” memo is reproduced in Pugh, Building IBM, MIT Press 1995, and is the subject of our previous post on the CDC 6600. Cray’s reply “It seems like Mr. Watson has answered his own question” is recorded in Murray, C. J., The Supermen: The Story of Seymour Cray and the Technical Wizards Behind the Supercomputer, Wiley, 1997. ↩
-
Smotherman, M., “IBM Advanced Computing Systems (ACS) – 1961-1969,” https://people.computing.clemson.edu/~mark/acs.html, accessed 2026-05-05, is the canonical reconstruction of the Project Y / ACS history. See also Smotherman, M., and Spicer, D., “Historical Reflections: IBM’s Single-Processor Supercomputer Efforts – Insights on the pioneering IBM Stretch and ACS projects,” Communications of the ACM 53(12):28-30, December 2010. ↩
-
Cocke’s biographical details from the IEEE Computer Society Computer Pioneer profile (Jurgen, R., 1991, IEEE Computer); the Mathematics Genealogy Project entry (advisor unknown); and The Register obituary of 19 July 2002 (https://www.theregister.com/2002/07/19/inventor_of_risc_chips_dies/). His father, Norman Atwater Cocke (1884-1974), was president of Duke Power Company 1947-1959 and the namesake of Lake Norman. ↩
-
Conway, L., “Reminiscences of the VLSI Revolution: How a series of failures triggered a paradigm shift in digital design,” IEEE Solid-State Circuits Magazine 4(4):8-31, Fall 2012. Conway’s IBM hire is dated 1964 by IBM personnel records; she records arriving at Yorktown in early 1965 in the 2012 memoir. ↩
-
Tomasulo 1967, Acknowledgements, p. 33: “The author wishes to acknowledge the contributions of Messrs. D. W. Anderson and D. M. Powers, who extended the original concept, and Mr. W. D. Silkman, who implemented all of the central control logic discussed in the paper.” ↩
-
Tomasulo 1967, abstract, p. 25. ↩
-
Tomasulo 1967, p. 27. Italics in original. ↩
-
Tomasulo 1967, p. 29: “In the Model 91 there are three add and two multiply/divide reservation stations. For simplicity they are treated as if they were actual units. Thus, in the future, we will speak of Adder 1 (A1), Adder 2 (A2), etc., and M/D 1 and M/D 2.” ↩
-
Tomasulo 1967, p. 30. ↩
-
Tomasulo 1967, p. 33. The full passage: “Without the CDB one iteration of the loop would use 17 cycles, allowing 4 per MD, 3 per AD and nothing for LD or STD. With the CDB one iteration requires 11 cycles. For this kind of code the CDB improves performance by about one-third.” ↩
-
Conway 2012, p. 8. ↩
-
Smotherman and Spicer, Communications of the ACM 53(12), December 2010: “Had the ACS-1 been built, its seven-issue, out-of-order design would have been the preeminent example of instruction-level parallelism. In ACS seven operations could be initiated in a single cycle – one in the branch unit, three in the fixed point unit, and three in the floating point unit – a technique later called superscalar processing.” See https://dl.acm.org/doi/fullHtml/10.1145/1859204.1859216. ↩
-
Conway 2012, p. 8. ↩
-
Conway 2012, p. 9. ↩
-
Conway, L., Randell, B., Rozenberg, D. P., and Senzig, D. N., “Dynamic Instruction Scheduling (DRAFT),” ACS Memorandum, IBM Advanced Computing Systems, San Jose, 23 February 1966. PDF of the IBM Confidential cover and full report at https://ai.eecs.umich.edu/people/conway/ACS/DIS/DIS.pdf. The “Brian Randell coined” remark is at Conway 2012, p. 9. ↩
-
DIS 1966, p. 19. ↩
-
Conway 2012, p. 11. ↩
-
Conway 2012, p. 11. The “impulsively executed, as if in hot-anger” phrasing is from Conway, L., “IBM-ACS: Reminiscences and Lessons Learned from a 1960’s Supercomputer Project,” in Jones, C. B., and Lloyd, J. L., eds., Dependable and Historic Computing, Springer, Berlin, 2011, pp. 185-224. ↩
-
Conway 2012, p. 18. The textbook is Mead, C., and Conway, L., Introduction to VLSI Systems, Addison-Wesley, Reading MA, 1980, ISBN 0-201-04358-0. ↩
-
IEEE Computer Society Computer Pioneer Award 2009 citation, https://www.computer.org/profiles/lynn-conway, accessed 2026-05-05. ↩
-
Diane Gherson, Senior Vice President of Human Resources at IBM, at “Tech Trailblazer and Transgender Pioneer: Lynn Conway in conversation with Diane Gherson,” virtual event for approximately 1200 IBM employees, 14 October 2020. Quoted in WRAL TechWire, “IBM apologizes 52 years later for firing transgender pioneering engineer,” 22 November 2020, https://wraltechwire.com/2020/11/22/ibm-apologizes-52-years-later-for-firing-transgender-pioneering-engineer/. ↩
-
Conway 2012, p. 26. ↩
-
Pugh-Johnson-Palmer 1991, op. cit. Customer-list cross-references: Columbia computinghistory.36091 page; ed-thelen.org comp-hist vs-ibm-360-91.html (transcribing the SLAC console placard at Computer History Museum); UCLA ARPANET role from Wikipedia IBM System/360 Model 91. The two 360/95 thin-film variants are documented at IT History Society, NASA Greenbelt acceptance press of 1 July 1968, and the Computer History Museum thin-film storage entry. ↩
-
GFDL machine timeline and the TI ASC #4 are documented in NOAA, Activities FY 80, Plans FY 81: With a Review of Twenty-Five Years of Research 1955-1980, NOAA Repository item 52156, Geophysical Fluid Dynamics Laboratory, September 1980, p. 19. The Manabe-Bryan 1969 paper is Manabe, S., and Bryan, K., “Climate Calculations with a Combined Ocean-Atmosphere Model,” Journal of the Atmospheric Sciences 26(4):786-789, July 1969; the “1200 hours of computing on a UNIVAC 1108” quote is on p. 787. NMC’s three 360/195s are documented in the NCEP/EMC retrospective “Development and Success of NCEP’s Global Forecast System,” 2019 American Meteorological Society Annual Meeting paper. ↩
-
Control Data Corp. v. International Business Machines Corp., 306 F. Supp. 839 (D. Minn. 1969), and the published procedural opinion. The case docket is D. Minn. Civ. Action No. 3-68-312 before Judge Philip Neville. The “Paper Machines and Phantom Computers” section title is documented in Reason magazine, “IBM: Producer or Predator,” April 1974, https://reason.com/1974/04/01/ibm/, accessed 2026-05-05. ↩
-
United States v. International Business Machines Corp., 69 Civ. 200 (S.D.N.Y. 1969), filed 17 January 1969 by Attorney General Ramsey Clark. Trial commenced 19 May 1975 before Judge David N. Edelstein. The 104 000 page transcript figure is from Levy, D., and Welzer, S., “System Error: How the IBM Antitrust Suit Raised Computer Prices,” Regulation 9(5/6):27-33, September-October 1985. The case was dismissed 8 January 1982 by Assistant Attorney General William F. Baxter as “without merit.” ↩
-
Settlement value is reconstructed from Wall Street Journal, “Litigation, CDC Settlement Seen As Set Back by Others Suing IBM,” 23 January 1973 (preserved in the Computer and Communications Industry Association collection at the Charles Babbage Institute, University of Minnesota); Reason April 1974; Pugh, Building IBM, MIT Press 1995; and Levy and Welzer 1985. Database destruction timeline 12-13 January 1973 is from CIA-FOIA-released NYT clipping CIA-RDP78-01092A000100040020-4. The “I don’t want a single document destroyed” quote is from Edelstein’s pretrial discovery rulings, summarised in In re International Business Machines Corp., 687 F.2d 591 (2d Cir. 1982). ↩
-
Smith, J. E., and Pleszkun, A. R., “Implementation of Precise Interrupts in Pipelined Processors,” Proceedings of the 12th Annual International Symposium on Computer Architecture, Boston MA, June 1985, pp. 36-44, DOI 10.1145/327070.327125. Republished as Smith and Pleszkun, “Implementing Precise Interrupts in Pipelined Processors,” IEEE Transactions on Computers 37(5):562-573, May 1988, DOI 10.1109/12.4607. PDF mirrored at https://www.cs.virginia.edu/~evans/greatworks/smith.pdf. ↩
-
Patterson, D. A., “Reduced Instruction Set Computers,” Communications of the ACM 28(1):8-21, January 1985, DOI 10.1145/2465.214917. Earlier polemical predecessor: Patterson, D. A., and Ditzel, D. R., “The Case for the Reduced Instruction Set Computer,” ACM SIGARCH Computer Architecture News 8(6):25-33, October 1980. ↩
-
Colwell, R. P., oral history interviewed by Paul N. Edwards, 24-25 August 2009, SIGMICRO Oral Histories, https://www.sigmicro.org/media/oralhistories/colwell.pdf, p. 92. ↩
-
Colwell oral history op. cit., p. 100. Colwell’s book The Pentium Chronicles: The People, Passion, and Politics Behind Intel’s Landmark Chips, Wiley/IEEE, 2006, gives a similar but less specific account. ↩
-
Colwell, R. P., and Steck, R. L., “A 0.6 micron BiCMOS Processor with Dynamic Execution,” Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, 16 February 1995. Pentium Pro launch documented at HPCwire, “200 MHz Intel Pentium Pro Benchmarks at 366 SPECint92,” 3 November 1995, https://www.hpcwire.com/1995/11/03/200-mhz-intel-pentium-pro-benchmarks-at-366-specint92/. Launch prices ran from $974 (150 MHz, 256 KB L2) to $1989 (200 MHz, 512 KB L2). ↩
-
The Apple M1 / Firestorm microarchitecture numbers come from reverse-engineering rather than from Apple documentation: dougallj, “Apple M1: Load and Store Queue Measurements,” 8 April 2021, https://dougallj.wordpress.com/2021/04/08/apple-m1-load-and-store-queue-measurements/, and dougallj, “Firestorm Overview,” https://dougallj.github.io/applecpu/firestorm.html. ↩
-
The Register obituary, “Inventor of RISC chips dies,” 19 July 2002, https://www.theregister.com/2002/07/19/inventor_of_risc_chips_dies/. ACM Turing Award 1987 citation: https://amturing.acm.org/award_winners/cocke_2083115.cfm. National Medal of Technology 1991, National Medal of Science 1994, IEEE Eckert-Mauchly Award 1985, Seymour Cray Award 1999. ↩
-
ACM Eckert-Mauchly Award 1997 citation, https://awards.acm.org/award_winners/tomasulo_8252171, accessed 2026-05-05. ↩
-
Tomasulo 1967, p. 33, conclusion. ↩